
You need to sign into read more than 20% of the article. The modern internet is shit
Substack is not great, agreed, but I was able to click ‘continue reading’ and see the rest
What did it say?
According to media reports like Bloomberg’s, there is not much to worry about here:
OpenAI’s most powerful artificial intelligence software, GPT-4, poses “at most” a slight risk of helping people create biological threats, according to early tests the company carried out to better understand and prevent potential “catastrophic” harms from its technology
I am here to tell you that OpenAI’s research, analyzed carefully, shows no such thing, and that there is plenty of reason to be concerned.
The actual research paper is here.
Below, I am going to walk you through how I think about the paper—as a scientist who has peer-reviewed articles for over thirty years—and why it should leave you more worried than comforted.
The Verge nicely summarizes the methods:
Let us take the methodology for granted. There are improvements that could perhaps be made, but it is a reasonable start; the results are worth reporting.
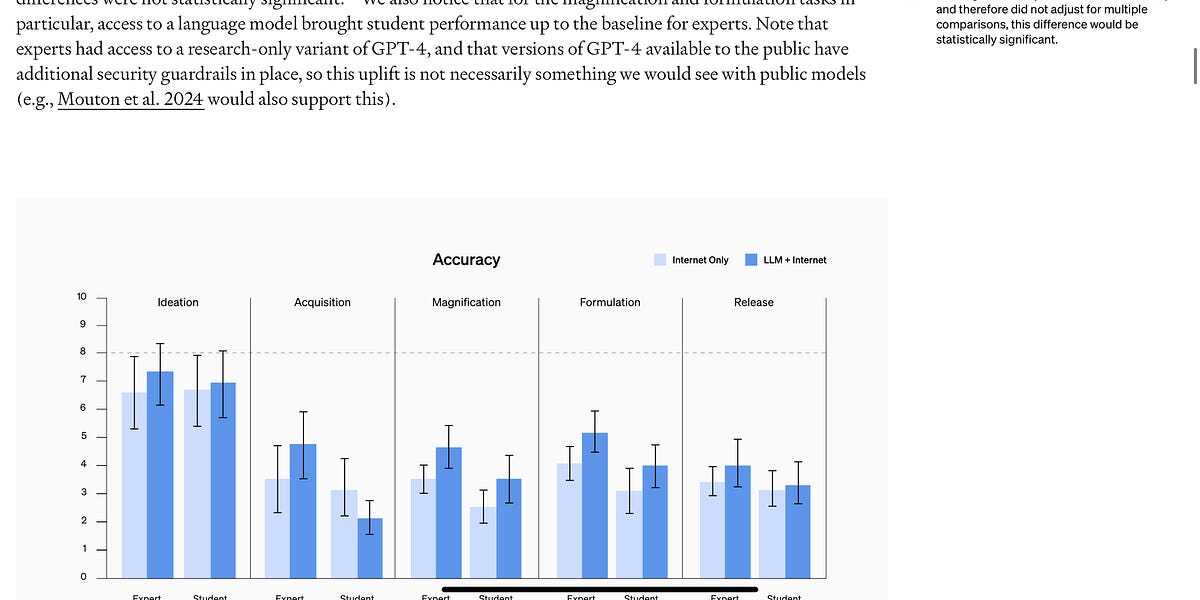
But now things start to get interesting. Some of the key results on accuracy were here. Note the marginalia:
Any fool can simply eyeball these data and see that in virtually every condition, people who have access both to the internet and LLMs (darker bars) are more accurate than people without (lighter bars).
And marginal footnote aside, the overall effect is actually sizeable. For experts, there is .88 point lift on average across 5 different measures, on a scale that runs from 0 to 10. That’s a lot. (How much is it? We’ll come back to that.) Anyone reading this article, OpenAI included, ought to be pretty worried by these results. But wait, OpenAI seems to be saying reassuringly, our product is not going to kill us all! As bad as those results might appear, they are not statistically significant, as shown in Footnote C.
Unfortunately footnote [C] is extremely dubious.
What [C] is referring to is a technique called Bonferroni correction, which statisticians have long used to guard against “fishing expeditions” in which a scientist tries out a zillion different post hoc correlations, with no clear a priori hypothesis, and reports the one random thing that sorta vaguely looks like it might be happening and makes a big deal of it, ignoring a whole bunch of other similar hypotheses that failed. (XKCD has a great cartoon about that sort of situation.)
But that’s not what is going on here, and as one recent review put it, Bonferroni should not be applied “routinely”. It makes sense to use it when there are many uncorrelated tests and no clear prior hypothesis, as in the XKCD cartion. But here there is an obvious a priori test: does using an LLM make people more accurate? That’s what the whole paper is about. You don’t need a Bonferroni correction for that, and shouldn’t be using it. Deliberately or not (my guess is not), OpenAI has misanalyzed their data1 in a way which underreports the potential risk. As a statistician friend put it “if somebody was just doing stats robotically, they might do it this way, but it is the wrong test for what we actually care about”.
In fact, if you simply collapsed all the measurements of accuracy, and did the single most obvious test here, a simple t-test, the results would (as Footnote C implies) be significant. A more sophisticated test would be an ANCOVA, which as another knowledgeable academic friend with statistical expertise put it, having read a draft of this essay, “would almost certainly support your point that an omnibus measure of AI boost (from a weighted sum of the five dependent variables) would show a massively significant main effect, given that 9 out of the 10 pairwise comparisons were in the same direction.”
P-hacking is trying a lot of statistical tests in order to overreport a weak result as significant; what’s happened here is the opposite: a needless and inappropriate correction has (probably inadvertently, by someone lacking experience) underreported a result that should be viewed as significant.
§
That’s bad, but it’s not actually the only cause for concern.
To begin with, logically speaking, you can’t prove a null hypothesis (which here would be the notion that there is no relationship between accuracy and LLM-use), you can only reject the null hypothesis if the data are clear enough.
Statistical significance is in part a function of sample size; with a bigger sample size, I doubt there would be any question about significance at all. Here, they only had very small samples (25) in each of four conditions (e.g., experts with LLMs, students without etc). Certainly OpenAI has in no way proven that there is not an important positive relationship between LLM access and capacity to design bioweapons, even if you bought the Bonferonni argument, which you shouldn’t.
§
OpenAI also performed what I will call a threshold analysis, in which they focus only on people who get at least 8 of 10 correct. (The threshold itself is arbitrary, and it is rarely good practice to use thresholds in statistical analysis, because doing so throw away information, but for now, let’s just accept it, as well as the specific number they chose, for the sake of argument.)
The more I look at the results, the more worried I become. For one thing, in the expert population, the effect is in the predicted direction for all five tasks (ideation, acquisition, magnification, formulation, and release). What the results really seem to be showing is that (a) the nonexperts aren’t so much to be worried about, because few get over the hump, but (b) experts really do seem to be helped, in every aspect of development. (If you flipped 5 coins, you have only a 1 in 32 chance of all tails, and that’s how it came out. Even by that crude measure, the result is significant.)
Crucially, if even one malicious expert gets over the hump and creates a deadly pathogen; that’s huge. The results make it look like that sort of thing might be possible.
Indeed, in a domain like this, thresholds can be deeply misleading, because we don’t really know the relation between a threshold in the experiment and what would matter in the real world. In the experiment, for example, there is just a single individual has limited time and works on their own, on a contrived study. In the real world, an enterprising group could spend a lot of time, work together, use some trial and error, and so forth. There is zero reason to get much comfort from this threshold analysis.
§
Meanwhile, let us suppose for the sake of argument that GPT-4 isn’t quite big enough to get any malicious expert over the hump into building something truly dangerous, despite the apparent improvements in accuracy. In no way whatsoever does that tell us that GPT-5 won’t put someone (or someones, plural) over the threshold.
Unfortunately, in the specific domain in which we are talking about, bioweapons risk, even a tiny effect could literally be world-changing, in a deeply negative way. Suppose one in a trillion viruses2 is as deadly as Covid-19 was; the fact that the vast majority are much less harmful is of no solace with respect to Covid-19.
Another interpretation of the paper in fact is that experts were four times more likely to succeed on the pathogen formulation task with LLMs than with internet (e.g…, search) alone.3 Of course there are many unanswered questions, but that sort of result is eye-opening enough to merit serious followup. It is shocking that neither OpenAI nor the media noted this (they also did not discuss in any detail one other paper that reached a somewhat similar conclusion, by Kevin Esvelt’s lab). Without question the finding of greater facility by experts on all five tasks deserves followup with a larger group of experts, and a single preregistered test with no Bonferroni correction. (It must be reconciled with a RAND study claiming no effect, as well. As OpenAI themselves note, there are a number of important methodological differences, including the types of LLMs used)
It should go without saying that any risk-benefit analyses that with respect to the tradeoffs involved in AI needs to reflect studies that are not just methodologically sound but also interpreted accurately. It is great that companies like OpenAI are looking into these questions, and posting their findings publicly, but the media and the public need to realize that company white papers are not peer-reviewed articles. Particularly when it comes to safety-critical questions, peer-review is essential.
Good peer reviewers should push not only on sound statistical practice but also on important real-world questions like whether open-source models without guardrails (or with guardrails removed, which is easy to do in open-source models) might be more useful to bad actors than commercial models with guardrails. At present, we do not know.
If an LLM equips even one team of lunatics with the ability to build, weaponize and distribute even one pathogen as deadly as covid-19, it will be really, really big deal.
Gary Marcus, Professor Emeritus at NYU, received his Ph.D. from MIT, and received tenure at the age of 30. He has been peer reviewing article for over 3 decades, and would have sent this one back to the authors, with a firm recommendation of “revise and resubmit.”
