Attached: 4 images
As many of you know, I posted recently about my experiences and outlook on Kagi, the paid search engine. It's gotten some positive press recently, ironically right after I made my blog post about why I no longer liked or trusted it. This blog post was called "Why I Lost Faith In Kagi" and was a pretty simple quick collection of my thoughts that I primarily wrote so it'd be easier to find again later to link to people when discussing Kagi versus making it a fedi thread I couldn't search for easily later. Across the four social media platforms I linked this blog post on, I'd say it got a total of about 40 likes and few reblogs.
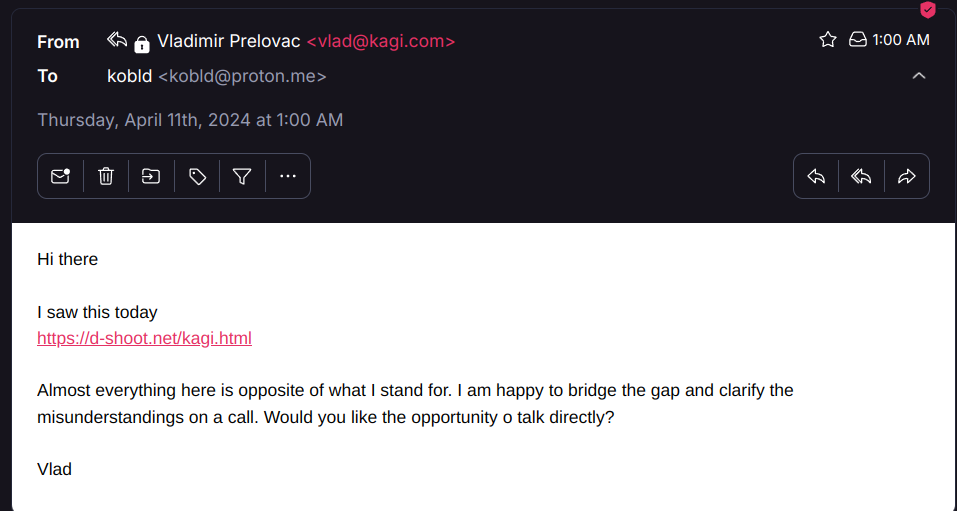
https://d-shoot.net/kagi.html
I say this because this morning I woke up to an email from Kagi's CEO, Vlad, who had seen the post and was upset about it. I have an email address listed on my blog (which is why I didn't bother removing it from these logs), which is what he sent his emails to. I am posting this entire email chain in this thread and will briefly post my thoughts about it, but I feel like it's something that needs to be seen. Please take note of the subject of the email as well (EDIT: It got cropped out sorry, the subject is "Fatih [sic] can not be lost"). Also, since the alt text would get extremely long with some of the transcripts, I've provided a text dump of the emails here for screen reader users and will offer a more abridged description in the alt text: https://d-shoot.net/files/kagiemails.txt
yall really are making me want to massively overextend and start that federated search engine project based on human-driven indexing and whichever APIs each instance wants to query and cache. yes, like a fancy web directory
maybe this is a good idea for a FreeAssembly project once Philthy’s in a good state? it’s a better idea than starting a shitty Wikipedia clone at least
Personally: I’d love to, but I have a conflicting non-compete so I’d definitely have to quit my job first and I’m not ready for that level of adulting. The good news is that if I ever do quit I’ll have a lot of relevant skills
(feels quite fucky to type the following without coming across as a naysayer; not quite the intended meaning, but… I guess you’ll see)
it’d probably be cool if this could exist, but also there’s a couple of extremely hard problems in going for it, along with a couple of (to my current knowledge) entirely unsolved ones
one of the presently-unsolved things I know of is that we don’t yet have anything like scalable performant homomorphic encryption so there’s no way to do fully-private query operations on a dataset, which thus gives way to the operator snooping space combined with user privacy angles. there are some technical solutions to some aspects of this, and a number of social things that would apply too


yall really are making me want to massively overextend and start that federated search engine project based on human-driven indexing and whichever APIs each instance wants to query and cache. yes, like a fancy web directory
maybe this is a good idea for a FreeAssembly project once Philthy’s in a good state? it’s a better idea than starting a shitty Wikipedia clone at least
Personally: I’d love to, but I have a conflicting non-compete so I’d definitely have to quit my job first and I’m not ready for that level of adulting. The good news is that if I ever do quit I’ll have a lot of relevant skills
(feels quite fucky to type the following without coming across as a naysayer; not quite the intended meaning, but… I guess you’ll see)
it’d probably be cool if this could exist, but also there’s a couple of extremely hard problems in going for it, along with a couple of (to my current knowledge) entirely unsolved ones
one of the presently-unsolved things I know of is that we don’t yet have anything like scalable performant homomorphic encryption so there’s no way to do fully-private query operations on a dataset, which thus gives way to the operator snooping space combined with user privacy angles. there are some technical solutions to some aspects of this, and a number of social things that would apply too
might be interesting either way
definitely a hell of a big project.
Omg so much tech jargon in this comment
welcome to TechTakes!
no, welcome wasn’t the right word now was it
maybe this is something you’re looking for idk https://github.com/StractOrg/stract they have their own index and their own crawler
covered by 404media https://www.404media.co/this-guy-is-building-an-open-source-search-engine-in-real-time/