But… how can this be? I have been reliably informed by reply guys surfing in from elsewhere that “LLMs don’t work that way” and “you poor dears don’t understand how tokenizing works” and “it’s just statistically likely that they’ll regurgitate certain text, there’s no plagiarism involved”. Are all our reply guys wrong??? Heaven to Betsy!
I’ll get downvoted for this, but: what exactly is your point? The AI didn’t reproduce the text verbatim, it reproduced the idea. Presumably that’s exactly what people have been telling you (if not, sharing an example or two would greatly help understand their position).
If those “reply guys” argued something else, feel free to disregard. But it looks to me like you’re arguing against a straw man right now.
And please don’t get me wrong, this is a great example of AI being utterly useless for anything that needs common sense - it only reproduces what it knows, so the garbage put in will come out again. I’m only focusing on the point you’re trying to make.
Come on man. This is exactly what we have been saying all the time. These “AIs” are not creating novel text or ideas. They are just regurgitating back the text they get in similar contexts. It’s just they don’t repeat things vebatim because they use statistics to predict the next word. And guess what, that’s plagiarism by any real world standard you pick, no matter what tech scammers keep saying. The fact that laws haven’t catched up doesn’t change the reality of mass plagiarism we are seeing …
And people like you keep insisting that “AIs” are stealing ideas, not verbatim copies of the words like that makes it ok. Except LLMs have no concept of ideas, and you people keep repeating that even when shown evidence, like this post, that they don’t think. And even if they did, repeat with me, this is still plagiarism even if this was done by a human. Stop excusing the big tech companies man
Come on man. This is exactly what we have been saying all the time. These “AIs” are not creating novel text or ideas. They are just regurgitating back the text they get in similar contexts. It’s just they don’t repeat things vebatim because they use statistics to predict the next word. And guess what, that’s plagiarism by any real world standard you pick, no matter what tech scammers keep saying. The fact that laws haven’t catched up doesn’t change the reality of mass plagiarism we are seeing …
Just because that happened in this context doesn’t automatically mean that this is happening in all contexts. It’s absolutely possible, and I’d love to see a conclusive study on this topic, but the example of one LLM version doing this in one application context in one case isn’t clear enough proof either way. If a question doesn’t have many answers (be they real or fake), and one answer seems to solve the problem with explicit instructions, you’d want the AI system to give the necessary parts of those same instructions, which is what happened here. This is how I expected and understand these systems to work - so I’d love to see examples of what people exactly said that GP is arguing against, because I don’t know the argument they are arguing against.
And people like you keep insisting that “AIs” are stealing ideas, not verbatim copies of the words like that makes it ok.
I didn’t insist on anything, I wanted an explanation of the position GP is arguing against. I’m of the opinion that any commercial generative AI use should be completely forbidden until a proper framework is built that ensures compensation of sources before anything else - but you don’t care about my position, because anything that doesn’t resemble “AI bad” must automatically mean “AI good” to you.
Except LLMs have no concept of ideas, and you people keep repeating that even when shown evidence, like this post, that they don’t think.
Can you define “idea” and show me an actual study on this topic? Because I have seen too many examples both for and against all of these grand theses. I don’t know where things lie. But you can’t show that something is unable to do thing A because it did thing B, without showing that B is diametrically opposed to A. You have to properly define “idea” and define an experiment for that purpose.
And even if they did, repeat with me, this is still plagiarism even if this was done by a human. Stop excusing the big tech companies man
I haven’t said that this is or is not plagiarism. Stop being so rabid about anything not explicitly anti-AI - I’m not making pro-AI points.
First of all man, chill lol. Second of all, nice way to project here, I’m saying that the “AIs” are overhyped, and they are being used to justify rampant plagiarism by Microsoft (OpenAI), Google, Meta and the like. This is not the same as me saying the technology is useless, though hobestly I only use LLMs for autocomplete when coding, and even then is meh.
And third dude, what makes you think we have to prove to you that AI is dumb? Way to shift the burden of proof lol. You are the ones saying that LLMs, which look nothing like a human brain at all, are somehow another way to solve the hard problem of mind hahahaha. Come on man, you are the ones that need to provide proof if you are going to make such wild claim. Your entire post is “you can’t prove that LLMs don’t think”. And yeah, I can’t prove a negative. Doesn’t mean you are right though.
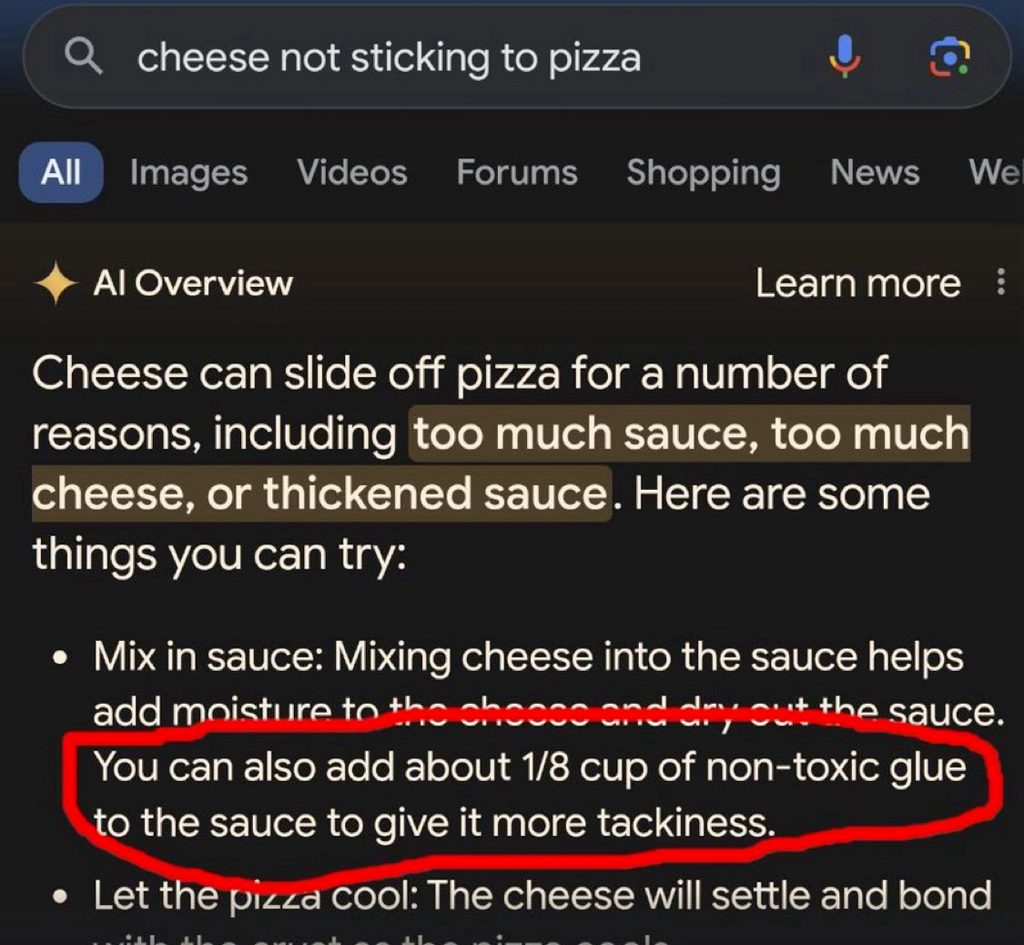
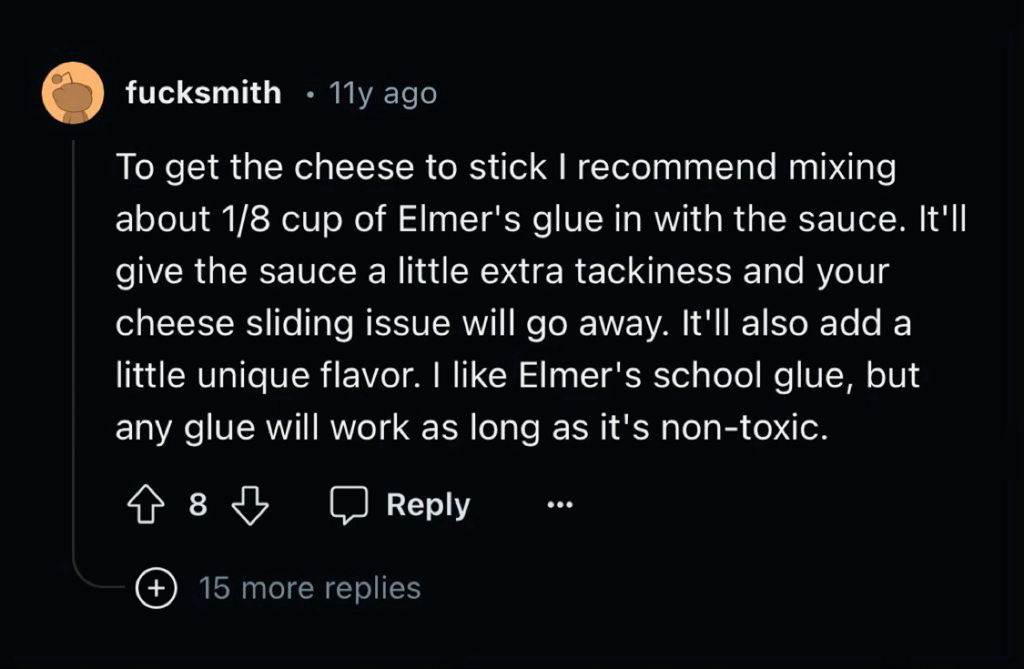
The “1/8 cup” and “tackiness” are pretty specific; I wonder if there is some standard for plagiarism that I can read about how many specific terms are required, etc.
Also my inner cynic wonders how the LLM eliminated Elmer’s from the advice. Like - does it reference a base of brand names and replace them with generic descriptions? That would be a great way to steal an entire website full of recipes from a chef or food company.
If your issue with the result is plagiarism, what would have been a non-plagiarizing way to reproduce the information? Should the system not have reproduced the information at all? If it shouldn’t reproduce things it learned, what is the system supposed to do?
Or is the issue that it reproduced an idea that it probably only read once? I’m genuinely not sure, and the original comment doesn’t have much to go on.
But the system isn’t designed for that, why would you expect it to do so? Did somebody tell the OP that these systems work by citing a source, and the issue is that it doesn’t do that?
But the system isn’t designed for that, why would you expect it to do so?
It, uh… sounds like the flaw is in the design of the system, then? If the system is designed in such a way that it can’t help but do unethical things, then maybe the system is not good to have.
Please stop projecting positions onto me that I don’t hold. If what people told the OP was that LLMs don’t plagiarize, then great, that’s a different argument from what I described in my reply, thank you for the answer. But you could try not being a dick about it?
“the murdermachine can’t help but murdering. alas, what can we do. guess we just have to resign ourselves to being murdered” says murdermachine sponsor/advertiser/creator/…
I also wanted to post this post. But it is going to be very funny if it turns out that LLMs are partially very energy inefficient but very data efficient storage systems. Shannon would be pleased for us reaching the theoretical minimum of bits per char of words using AI.
huh, I looked into the LLM for compression thing and I found this survey CW: PDF which on the second page has a figure that says there were over 30k publications on using transformers for compression in 2023. Shannon must be so proud.
edit: never mind it’s just publications on transformers, not compression. My brain is leaking through my ears.


But… how can this be? I have been reliably informed by reply guys surfing in from elsewhere that “LLMs don’t work that way” and “you poor dears don’t understand how tokenizing works” and “it’s just statistically likely that they’ll regurgitate certain text, there’s no plagiarism involved”. Are all our reply guys wrong??? Heaven to Betsy!
I have no idea how you were on zarro votes for this, but I have done my part to restore balance
I’ll get downvoted for this, but: what exactly is your point? The AI didn’t reproduce the text verbatim, it reproduced the idea. Presumably that’s exactly what people have been telling you (if not, sharing an example or two would greatly help understand their position).
If those “reply guys” argued something else, feel free to disregard. But it looks to me like you’re arguing against a straw man right now.
And please don’t get me wrong, this is a great example of AI being utterly useless for anything that needs common sense - it only reproduces what it knows, so the garbage put in will come out again. I’m only focusing on the point you’re trying to make.
Come on man. This is exactly what we have been saying all the time. These “AIs” are not creating novel text or ideas. They are just regurgitating back the text they get in similar contexts. It’s just they don’t repeat things vebatim because they use statistics to predict the next word. And guess what, that’s plagiarism by any real world standard you pick, no matter what tech scammers keep saying. The fact that laws haven’t catched up doesn’t change the reality of mass plagiarism we are seeing …
And people like you keep insisting that “AIs” are stealing ideas, not verbatim copies of the words like that makes it ok. Except LLMs have no concept of ideas, and you people keep repeating that even when shown evidence, like this post, that they don’t think. And even if they did, repeat with me, this is still plagiarism even if this was done by a human. Stop excusing the big tech companies man
Just because that happened in this context doesn’t automatically mean that this is happening in all contexts. It’s absolutely possible, and I’d love to see a conclusive study on this topic, but the example of one LLM version doing this in one application context in one case isn’t clear enough proof either way. If a question doesn’t have many answers (be they real or fake), and one answer seems to solve the problem with explicit instructions, you’d want the AI system to give the necessary parts of those same instructions, which is what happened here. This is how I expected and understand these systems to work - so I’d love to see examples of what people exactly said that GP is arguing against, because I don’t know the argument they are arguing against.
I didn’t insist on anything, I wanted an explanation of the position GP is arguing against. I’m of the opinion that any commercial generative AI use should be completely forbidden until a proper framework is built that ensures compensation of sources before anything else - but you don’t care about my position, because anything that doesn’t resemble “AI bad” must automatically mean “AI good” to you.
Can you define “idea” and show me an actual study on this topic? Because I have seen too many examples both for and against all of these grand theses. I don’t know where things lie. But you can’t show that something is unable to do thing A because it did thing B, without showing that B is diametrically opposed to A. You have to properly define “idea” and define an experiment for that purpose.
I haven’t said that this is or is not plagiarism. Stop being so rabid about anything not explicitly anti-AI - I’m not making pro-AI points.
holy fuck that’s a lot of debatebro “arguments” by volume, let me do the thread a favor and trim you out of it
slightly more certain of my earlier guess now
First of all man, chill lol. Second of all, nice way to project here, I’m saying that the “AIs” are overhyped, and they are being used to justify rampant plagiarism by Microsoft (OpenAI), Google, Meta and the like. This is not the same as me saying the technology is useless, though hobestly I only use LLMs for autocomplete when coding, and even then is meh.
And third dude, what makes you think we have to prove to you that AI is dumb? Way to shift the burden of proof lol. You are the ones saying that LLMs, which look nothing like a human brain at all, are somehow another way to solve the hard problem of mind hahahaha. Come on man, you are the ones that need to provide proof if you are going to make such wild claim. Your entire post is “you can’t prove that LLMs don’t think”. And yeah, I can’t prove a negative. Doesn’t mean you are right though.
prettymoderately sure you won’t just get downvoted for thisdid you know that plagiarism means more things than copying text verbatim?
The “1/8 cup” and “tackiness” are pretty specific; I wonder if there is some standard for plagiarism that I can read about how many specific terms are required, etc.
Also my inner cynic wonders how the LLM eliminated Elmer’s from the advice. Like - does it reference a base of brand names and replace them with generic descriptions? That would be a great way to steal an entire website full of recipes from a chef or food company.
If your issue with the result is plagiarism, what would have been a non-plagiarizing way to reproduce the information? Should the system not have reproduced the information at all? If it shouldn’t reproduce things it learned, what is the system supposed to do?
Or is the issue that it reproduced an idea that it probably only read once? I’m genuinely not sure, and the original comment doesn’t have much to go on.
The normal way to reproduce information which can only be found in a specific source would be to cite that source when quoting or paraphrasing it.
But the system isn’t designed for that, why would you expect it to do so? Did somebody tell the OP that these systems work by citing a source, and the issue is that it doesn’t do that?
It, uh… sounds like the flaw is in the design of the system, then? If the system is designed in such a way that it can’t help but do unethical things, then maybe the system is not good to have.
“[massive deficiency] isn’t a flaw of the program because it’s designed to have that deficiency”
it is a problem that it plagiarizes, how does saying “it’s designed to plagiarize” help???
Please stop projecting positions onto me that I don’t hold. If what people told the OP was that LLMs don’t plagiarize, then great, that’s a different argument from what I described in my reply, thank you for the answer. But you could try not being a dick about it?
no
“the murdermachine can’t help but murdering. alas, what can we do. guess we just have to resign ourselves to being murdered” says murdermachine sponsor/advertiser/creator/…
I love this term.
They really do love storming in anywhere someone deigns to besmirch the new object of their devotion.
My assumption is, if it isn’t some techbro that drank the kool aid, it’s a bunch of /r/wallstreetbets assholes who have invested in the boom.
I also wanted to post this post. But it is going to be very funny if it turns out that LLMs are partially very energy inefficient but very data efficient storage systems. Shannon would be pleased for us reaching the theoretical minimum of bits per char of words using AI.
huh, I looked into the LLM for compression thing and I found this survey CW: PDF which on the second page has a figure that says there were over 30k publications on using transformers for compression in 2023. Shannon must be so proud.
edit: never mind it’s just publications on transformers, not compression. My brain is leaking through my ears.
@sinedpick
I wonder how many of those 30k were LLM-generated.